Amazon EMR Spark performance tuning sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail with ahrefs author style and brimming with originality from the outset.
Spark, a powerful tool for big data processing, requires meticulous tuning for optimal performance on Amazon EMR. In this guide, we delve into key strategies to fine-tune Spark, enhancing its efficiency and speed in handling large datasets.
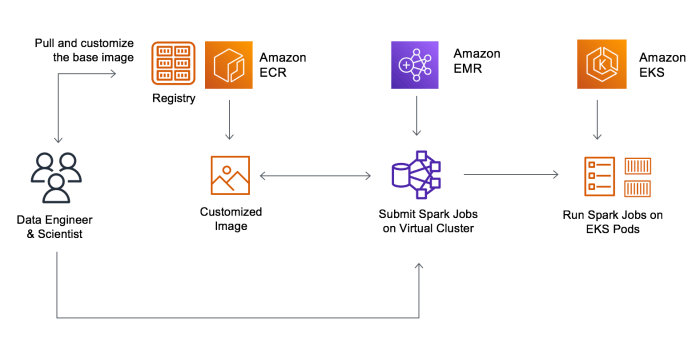
Overview of Amazon EMR Spark Performance Tuning

Optimizing Spark performance on Amazon EMR is crucial for efficient big data processing. By tuning Spark, users can enhance the speed, scalability, and overall performance of their data processing tasks on the cloud platform.
When it comes to managing vast amounts of data, companies often turn to AWS data lake services for a comprehensive solution. These services provide a scalable and secure platform for storing and analyzing data efficiently.
Importance of Optimizing Spark Performance
- Maximizes resource utilization: Performance tuning ensures that Spark utilizes resources effectively, minimizing wastage and improving overall efficiency.
- Enhances speed and responsiveness: Tuning Spark can significantly boost the speed of data processing tasks, resulting in quicker insights and analysis.
- Reduces costs: Improved performance leads to reduced processing times, which can translate to cost savings for users running big data workloads on Amazon EMR.
Benefits of Tuning Spark for Better Performance, Amazon EMR Spark performance tuning
- Increased productivity: Faster processing speeds enable users to analyze data more quickly and make informed decisions in a timely manner.
- Scalability: Performance tuning allows Spark to handle larger datasets and more complex processing tasks, ensuring scalability as data volumes grow.
- Improved user experience: By optimizing Spark performance, users can enjoy a smoother and more responsive data processing experience on Amazon EMR.
Main Objectives of Performance Tuning for Amazon EMR Spark
- Optimizing resource allocation: Ensuring that Spark tasks are allocated the right amount of resources to prevent bottlenecks and maximize efficiency.
- Tuning Spark configurations: Fine-tuning Spark settings such as memory allocation, parallelism, and caching to optimize performance for specific workloads.
- Monitoring and troubleshooting: Regularly monitoring Spark performance metrics and identifying and resolving any issues that may impact performance.
Monitoring and Profiling Tools for Spark Performance

Monitoring and profiling tools play a crucial role in optimizing Spark performance on Amazon EMR. These tools help in identifying bottlenecks and improving the overall efficiency of Spark applications.
Key Monitoring Tools for Spark Performance
- Amazon CloudWatch: Provides real-time monitoring of cluster resources, application metrics, and logs, allowing users to track performance and detect anomalies.
- Ganglia: Offers detailed insights into cluster health, resource usage, and task execution, enabling users to monitor Spark job performance effectively.
- Prometheus: Facilitates monitoring of various Spark metrics and performance indicators, aiding in proactive performance management and troubleshooting.
Significance of Profiling Tools in Optimizing Spark Performance on EMR
Profiling tools such as Spark UI and Spark History Server are essential for gaining deep insights into job execution details, resource utilization, and task performance. By analyzing profiling data, users can identify inefficiencies, optimize resource allocation, and fine-tune Spark configurations for enhanced performance.
Role of Monitoring Tools in Identifying Performance Bottlenecks
Monitoring tools help in pinpointing performance bottlenecks by tracking cluster health, resource utilization, and job execution metrics in real-time. By analyzing monitoring data, users can identify areas of improvement, optimize resource allocation, and troubleshoot issues that impact Spark performance on Amazon EMR.
Configuration Best Practices for Spark Performance: Amazon EMR Spark Performance Tuning
When it comes to optimizing Spark performance on Amazon EMR, configuring the right settings is crucial. By following best practices for configuration, you can significantly enhance the performance of your Spark jobs.
Role of Memory Management in Optimizing Spark Performance
Memory management plays a vital role in optimizing Spark performance. It is essential to allocate memory efficiently to different components of Spark to ensure smooth execution of jobs. Here are some key points to consider:
- Utilize memory fractions wisely to balance between storage memory and execution memory.
- Adjust the size of the shuffle memory to optimize performance for tasks involving data shuffling.
- Monitor garbage collection activity to avoid memory leaks and optimize memory usage.
Impact of Various Configuration Parameters on Spark Job Execution Times
Various configuration parameters can have a significant impact on Spark job execution times. It is essential to fine-tune these parameters based on your specific workload and cluster configuration. Here are some key parameters to consider:
| Parameter | Impact |
|---|---|
spark.executor.memory | Specifies the amount of memory to allocate per executor, impacting task execution efficiency. |
spark.shuffle.partitions | Determines the number of partitions to use when shuffling data, affecting job parallelism and performance. |
spark.default.parallelism | Sets the default number of partitions for RDDs, influencing the distribution of workload across executors. |
Data Partitioning and Optimization Techniques

Data partitioning plays a crucial role in optimizing Spark job performance on Amazon EMR. By distributing data across multiple nodes, Spark can parallelize processing tasks, leading to improved efficiency and faster execution times.
Impact of Data Partitioning on Spark Job Performance
- Proper data partitioning can significantly reduce shuffle operations, which are resource-intensive and can bottleneck Spark jobs.
- Well-partitioned data allows Spark to distribute work evenly across nodes, leveraging the parallel processing capabilities of the cluster.
- Improper partitioning can lead to skewed data distribution, causing certain tasks to take longer than others and impacting overall job performance.
Strategies for Optimizing Data Partitioning
- Utilize the `repartition` or `coalesce` functions in Spark to adjust the number of partitions based on the data size and cluster resources.
- Analyze the data distribution and skewness using tools like Spark UI or Spark History Server to identify optimal partitioning strategies.
- Consider using custom partitioners or partitioning keys that evenly distribute data based on application requirements.
Influence of Partitioning Key on Spark Tasks’ Efficiency
- The choice of partitioning key directly impacts how data is distributed across partitions, affecting the workload balance and task execution times.
- Selecting a proper partitioning key can minimize data skewness and optimize data processing, leading to faster and more efficient Spark tasks.
- Choosing a partitioning key that aligns with the data access patterns and join operations in the Spark application can enhance overall performance.
In conclusion, mastering the art of Amazon EMR Spark performance tuning is essential for unlocking the full potential of Spark in processing big data on EMR. By implementing the best practices Artikeld and leveraging monitoring tools, you can significantly boost Spark’s performance and efficiency, leading to faster data processing and analysis.
For businesses looking to optimize their storage costs, cost-efficient AWS storage services offer a cost-effective solution without compromising on performance. By utilizing these services, organizations can save money while ensuring data accessibility and durability.
Utilizing DynamoDB for big data applications can help businesses handle large volumes of data efficiently. With its high performance and scalability, DynamoDB is a popular choice for organizations looking to manage big data effectively.




{kind=link}