AWS big data workflow automation revolutionizes data management by leveraging powerful AWS tools to streamline processes and enhance efficiency. As businesses navigate the complexities of big data, this innovative solution offers a seamless approach to automating workflows and optimizing data operations.
In this comprehensive guide, we delve into the intricacies of AWS big data workflow automation, exploring key components, best practices, and real-world applications that showcase the transformative impact of this cutting-edge technology.
Overview of AWS Big Data Workflow Automation

AWS big data workflow automation involves using Amazon Web Services (AWS) to streamline and optimize the process of managing and analyzing large volumes of data. This automation helps organizations improve efficiency, reduce manual errors, and scale their data processing capabilities.
Benefits of Implementing AWS Big Data Workflow Automation
- Increased efficiency: Automation eliminates manual tasks, reducing the time and resources required for data processing.
- Improved accuracy: By minimizing human intervention, AWS automation reduces the risk of errors in data analysis and processing.
- Scalability: Automation allows for seamless scaling of data workflows to handle growing volumes of data without significant manual intervention.
- Cost-effectiveness: By streamlining processes and increasing efficiency, AWS automation helps organizations save on operational costs.
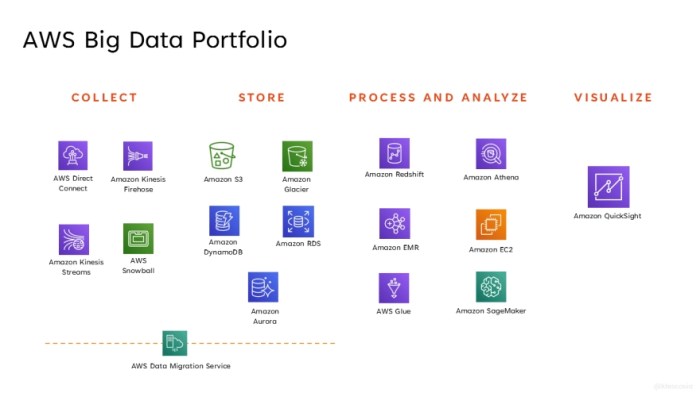
Key Components and Tools Used in AWS Big Data Workflow Automation
- AWS Glue: A fully managed extract, transform, and load (ETL) service that simplifies the process of preparing and loading data for analysis.
- AWS Step Functions: Helps coordinate multiple AWS services into serverless workflows, enabling automation of complex data processing tasks.
- Amazon S3: Provides scalable object storage for data storage, retrieval, and analysis, essential for managing big data workflows.
- Amazon EMR: A managed Hadoop framework that simplifies big data processing, making it easier to set up, operate, and scale.
Setting Up AWS Infrastructure for Big Data Workflow Automation: AWS Big Data Workflow Automation
To effectively automate big data workflows on AWS, it is crucial to set up the infrastructure correctly. This involves configuring various AWS services and following best practices to ensure efficiency and scalability.
Configuring AWS Services
When setting up AWS infrastructure for big data workflow automation, it is essential to consider the following steps:
- Choose the right storage solution: Utilize Amazon S3 for scalable, reliable, and cost-effective storage of big data sets.
- Select the appropriate compute resources: Use Amazon EC2 instances or AWS Lambda functions based on the processing requirements of your workflows.
- Implement scalable data processing: Leverage Amazon EMR for distributed data processing using popular frameworks like Apache Spark or Hadoop.
- Set up data orchestration: Utilize AWS Step Functions or Apache Airflow for orchestrating complex workflows and managing dependencies between tasks.
- Enable real-time data processing: Use Amazon Kinesis for real-time data streaming and processing to handle live data feeds efficiently.
Best Practices for Designing AWS Infrastructure
When designing an efficient AWS infrastructure for big data workflow automation, consider the following best practices:
- Implement security measures: Secure your data using AWS Identity and Access Management (IAM) roles, encryption, and network security protocols.
- Optimize cost management: Utilize AWS Cost Explorer and AWS Budgets to monitor and optimize your spending on AWS services.
- Design for scalability: Use auto-scaling features and elastic load balancing to ensure your infrastructure can handle varying workloads effectively.
- Monitor performance: Set up Amazon CloudWatch alarms and metrics to monitor the performance of your infrastructure and workflows in real-time.
Comparison of AWS Services
When evaluating different AWS services for automating big data workflows, consider the following comparisons:
- Amazon EMR vs. AWS Glue: Amazon EMR is ideal for running distributed processing frameworks, while AWS Glue is a fully managed ETL service for data integration.
- Amazon Kinesis vs. AWS Data Pipeline: Amazon Kinesis is designed for real-time data streaming and processing, while AWS Data Pipeline is a data orchestration service for batch processing.
- Amazon S3 vs. Amazon EBS: Amazon S3 is object storage suitable for storing large amounts of unstructured data, while Amazon EBS provides block storage for EC2 instances.
Implementing Data Ingestion in AWS Big Data Workflow

Data ingestion in AWS involves the process of importing and transferring large volumes of data from different sources into the AWS environment for further processing and analysis. This step is crucial in setting up a big data workflow to ensure that the required data is available for analytics and other downstream tasks.
Data Ingestion Process using AWS Services
- AWS Data Pipeline: AWS Data Pipeline is a web service that helps you schedule regular data movement and processing tasks across various AWS services. It allows you to define data processing workflows and automate data movement between different AWS services.
- AWS Glue: AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It can automatically discover, catalog, and transform data from various sources into a format suitable for analysis.
- Amazon Kinesis: Amazon Kinesis is a platform for streaming data on AWS, which can be used to collect, process, and analyze real-time, streaming data. It enables you to ingest data from various sources and make it available for real-time analytics and processing.
Data Ingestion Challenges and AWS Solutions
- Volume and Velocity: Handling large volumes of data at high velocity can be challenging. AWS offers scalable services like Amazon S3, Amazon Kinesis, and AWS Glue to efficiently ingest and process large amounts of data in real-time.
- Data Variety: Dealing with diverse data formats and sources can be complex. AWS provides services like AWS Glue that can automatically discover and catalog various data sources, making it easier to ingest and process diverse data types.
- Data Quality: Ensuring data quality during ingestion is crucial for accurate analysis. AWS services like AWS Glue and Amazon Kinesis provide capabilities to clean, transform, and validate data during the ingestion process to maintain data integrity.
Examples of Data Sources for Ingestion in AWS, AWS big data workflow automation
- Structured Data: Relational databases, CSV files, and spreadsheets are common examples of structured data sources that can be ingested into AWS for analysis using services like AWS Glue.
- Unstructured Data: Text documents, log files, and social media feeds are examples of unstructured data sources that can be ingested into AWS for text analytics and sentiment analysis using services like Amazon Kinesis.
- Semi-structured Data: JSON, XML, and Parquet files are examples of semi-structured data sources that can be ingested into AWS for analysis using services like AWS Glue for schema discovery and transformation.
Data Processing and Transformation with AWS Tools

AWS offers a wide range of tools to facilitate data processing and transformation tasks for big data workflows. These tools are designed to handle large volumes of data efficiently and enable organizations to derive valuable insights from their data.
AWS Data Pipeline
AWS Data Pipeline is a web service that helps users schedule and automate the movement and transformation of data. It allows users to define data processing workflows and manage dependencies between different data processing tasks. With AWS Data Pipeline, users can easily create complex data processing pipelines without the need for manual intervention.
Amazon EMR (Elastic MapReduce)
Amazon EMR is a managed Hadoop framework that simplifies the process of running big data processing tasks. It provides a scalable, secure, and cost-effective solution for processing large amounts of data using popular frameworks like Apache Spark and Apache Hadoop. Amazon EMR can be integrated with other AWS services to create end-to-end data processing workflows.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It automatically discovers and catalogs data, generates ETL code to transform data, and manages the execution of data processing workflows. AWS Glue simplifies the process of data transformation and enables users to create scalable and efficient data pipelines.
Case Study: Data Processing and Transformation with AWS
A retail company wanted to analyze customer behavior data to improve marketing strategies. They used AWS Data Pipeline to schedule data ingestion from various sources, Amazon EMR for processing and analyzing the data, and AWS Glue for transforming and loading the processed data into a data warehouse. By leveraging these AWS tools, the company was able to automate the entire data processing workflow, leading to faster insights and improved decision-making.
Automating Workflows with AWS Step Functions
AWS Step Functions play a crucial role in automating big data workflows by providing a reliable way to coordinate multiple AWS services into serverless workflows. These workflows can be designed to handle complex sequences of tasks, error handling, and concurrency, making it easier to manage and monitor the workflow execution.
Illustrative Scenario of Workflow Automation with AWS Step Functions
- Create a Step Function to trigger data ingestion from Amazon S3 to Amazon Redshift when new data arrives.
- Define a sequence of tasks within the Step Function to validate, transform, and load the data into the Redshift data warehouse.
- Include error handling mechanisms in the workflow to retry failed tasks and manage exceptions effectively.
- Monitor the workflow execution using AWS CloudWatch to track the progress and performance of each task.
Advantages of Using AWS Step Functions for Workflow Automation
- Scalability: Step Functions can scale automatically to handle high volumes of data processing tasks without manual intervention.
- Reliability: The built-in error handling and retry mechanisms ensure that workflows are executed reliably and consistently.
- Visibility: Step Functions provide detailed visibility into workflow execution, allowing you to track each step and identify bottlenecks or issues.
- Cost-Effective: By automating workflows with Step Functions, you can optimize resource utilization and reduce operational costs associated with manual intervention.
Unlock the full potential of your data infrastructure with AWS big data workflow automation. By embracing automation and harnessing the capabilities of AWS tools, organizations can achieve unprecedented levels of scalability, agility, and data-driven insights. Stay ahead of the curve and propel your business towards success in the era of big data with AWS big data workflow automation.
When it comes to handling big data on AWS, two popular options are AWS Glue and EMR. AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. On the other hand, Amazon EMR (Elastic MapReduce) is a big data platform that allows you to process large amounts of data using open-source tools like Apache Spark and Hadoop.
For storing large amounts of data in a scalable and cost-effective way on AWS, object storage is the way to go. Object storage allows you to store and retrieve large amounts of unstructured data, making it ideal for big data applications. With features like high durability, scalability, and low cost, object storage on AWS is perfect for big data workloads.
One of the most popular services for storing and retrieving big data on AWS is Amazon S3. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. With features like versioning, encryption, and lifecycle policies, Amazon S3 is the perfect choice for storing and analyzing big data on AWS.




{kind=link}