AWS Lambda for data processing revolutionizes the way data is handled, offering a seamless and efficient solution through serverless computing. Dive into the world of AWS Lambda as we explore its capabilities and benefits in streamlining data processing tasks.
Overview of AWS Lambda for data processing
AWS Lambda is a serverless computing service provided by Amazon Web Services (AWS) that allows developers to run code in response to events without the need to provision or manage servers. When it comes to data processing, AWS Lambda offers a cost-effective and scalable solution for processing large volumes of data efficiently.
Benefits of using AWS Lambda for data processing
- Scalability: AWS Lambda automatically scales based on the volume of incoming data, ensuring that processing tasks are completed in a timely manner.
- Cost-effectiveness: With AWS Lambda, you only pay for the compute time used to execute your code, making it a cost-effective option for data processing tasks.
- Flexibility: Developers can use various programming languages to write functions that process data, providing flexibility in implementing data processing solutions.
- Integration with other AWS services: AWS Lambda seamlessly integrates with other AWS services such as Amazon S3, Amazon DynamoDB, and Amazon RDS, making it easy to build end-to-end data processing pipelines.
Real-world use cases of AWS Lambda for data processing
- Real-time data processing: AWS Lambda can be used to process real-time data streams from sources such as IoT devices, social media platforms, or web applications.
- Data transformation: Developers can leverage AWS Lambda to transform and enrich data before storing it in a database or data warehouse.
- Automated data backups: AWS Lambda functions can be scheduled to automatically backup and archive data from various sources, ensuring data integrity and availability.
Setting up AWS Lambda for data processing

To set up AWS Lambda for data processing, follow these steps:
Creating an AWS Lambda function
- Create a new Lambda function in the AWS Management Console.
- Choose a blueprint or create a custom function from scratch.
- Configure the function settings, including memory allocation, timeout, and IAM role.
- Write the function code in the chosen programming language.
- Test the function locally or using sample data.
- Save and deploy the function to AWS Lambda.
Configuration options for AWS Lambda
- Memory allocation: Allocate the appropriate amount of memory based on the data processing requirements to optimize performance.
- Timeout settings: Adjust the timeout duration to ensure the function completes processing within the specified time limit.
- Environment variables: Use environment variables to pass configuration values or sensitive information to the function.
- Triggers: Configure triggers to automatically invoke the Lambda function based on events from other AWS services or external sources.
Tips for optimizing performance
- Avoid unnecessary dependencies in the function code to reduce execution time.
- Implement parallel processing or batching techniques for handling large volumes of data efficiently.
- Monitor the function performance using AWS CloudWatch metrics and logs to identify bottlenecks and optimize resource allocation.
- Consider using provisioned concurrency to reduce cold start times and improve response times for frequently invoked functions.
Integrating AWS Lambda with other AWS services

AWS Lambda can be seamlessly integrated with other AWS services such as Amazon S3, Amazon DynamoDB, and Amazon RDS to enhance data processing capabilities. By leveraging the strengths of these services in conjunction with AWS Lambda, users can create powerful workflows for efficient data processing tasks.
Integration with Amazon S3
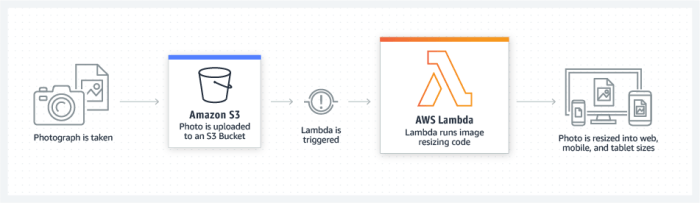
Amazon S3 is a popular object storage service that can be integrated with AWS Lambda to store and retrieve data during data processing tasks. When a file is uploaded to an S3 bucket, AWS Lambda can automatically trigger a function to process the data, enabling seamless processing without manual intervention.
Integration with Amazon DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service that can be integrated with AWS Lambda for real-time data processing. By using DynamoDB streams, changes to the database can trigger AWS Lambda functions, allowing for immediate data processing and analysis.
Integration with Amazon RDS
Amazon RDS is a relational database service that can be integrated with AWS Lambda for structured data processing tasks. By setting up triggers in RDS instances, changes to the database can invoke AWS Lambda functions, enabling efficient processing of relational data at scale.
Advantages of leveraging other AWS services with AWS Lambda, AWS Lambda for data processing
- Scalability: By combining AWS Lambda with other services, users can easily scale their data processing workflows based on demand without worrying about infrastructure management.
- Cost-effectiveness: Leveraging serverless computing with AWS Lambda and other AWS services can help reduce operational costs, as users only pay for the resources they consume.
- Flexibility: Integrating AWS Lambda with a variety of AWS services provides users with the flexibility to design custom data processing workflows tailored to their specific requirements.
Examples of workflows with AWS Lambda and other AWS services
For example, a common workflow involves triggering an AWS Lambda function when a new file is uploaded to an S3 bucket. The function can then process the file and store the results in an Amazon DynamoDB table for further analysis.
Monitoring and troubleshooting AWS Lambda functions: AWS Lambda For Data Processing

Monitoring and troubleshooting AWS Lambda functions are essential for ensuring smooth data processing operations. By utilizing the right tools and methods, you can effectively monitor performance and address any issues that may arise during data processing.
Tools and methods for monitoring AWS Lambda functions
- CloudWatch Metrics: AWS Lambda automatically sends metrics to Amazon CloudWatch, allowing you to monitor key performance indicators such as invocation counts, error rates, and duration.
- CloudWatch Logs: You can access logs generated by AWS Lambda functions in CloudWatch Logs, enabling you to track and troubleshoot issues by analyzing log data.
- X-Ray: AWS X-Ray provides tracing capabilities that help you identify performance bottlenecks and understand the execution flow of your Lambda functions.
Common issues and troubleshooting
- Timeout Errors: If your Lambda function exceeds the configured timeout value, you may encounter timeout errors. To troubleshoot, consider optimizing function code or increasing the timeout setting.
- Memory Errors: Insufficient memory allocation can lead to out-of-memory errors. Adjust the memory configuration based on workload requirements to resolve such issues.
- Permission Errors: Ensure that Lambda functions have the necessary permissions to access AWS resources. Use AWS Identity and Access Management (IAM) roles to grant appropriate permissions.
Best practices for logging and debugging
- Enable Detailed Logging: Implement thorough logging within Lambda functions to capture relevant information for debugging purposes.
- Use CloudWatch Logs Insights: Leverage CloudWatch Logs Insights to query and analyze log data efficiently, allowing you to identify and troubleshoot issues effectively.
- Integration with AWS Step Functions: Integrate Lambda functions with AWS Step Functions to orchestrate complex workflows and facilitate easier debugging and error handling.
In conclusion, AWS Lambda emerges as a powerful tool for data processing, enhancing productivity and scalability while simplifying complex operations. Embrace the future of serverless computing with AWS Lambda for unparalleled data processing efficiency.
When it comes to data archiving, Amazon S3 Glacier is a popular choice among businesses for its cost-effective storage solutions. With Data archiving with Amazon S3 Glacier , companies can securely store large amounts of data for long-term retention. Additionally, automating data pipelines with AWS offers efficiency and scalability in managing data workflows. Learn more about Data pipeline automation with AWS to streamline your data processing tasks.
Furthermore, Amazon Kinesis provides real-time data streaming capabilities for various use cases, enabling businesses to analyze and react to data instantly. Explore the possibilities of Amazon Kinesis use cases to leverage this powerful tool for your data-driven strategies.
When it comes to data archiving, Amazon S3 Glacier is a popular choice among businesses for its cost-effective storage solutions. With Data archiving with Amazon S3 Glacier , organizations can securely store their data for long-term retention. Meanwhile, for data pipeline automation, AWS offers powerful tools and services that streamline the process. Learn more about Data pipeline automation with AWS to improve efficiency and productivity.
Additionally, Amazon Kinesis has various use cases in real-time data streaming and analytics. Explore the possibilities with Amazon Kinesis use cases to harness the full potential of your data.




{kind=link}