Big data ETL tools on AWS revolutionize data processing, offering efficient solutions for handling large datasets. Dive into the world of ETL tools on AWS with a focus on simplifying complex data workflows.
Explore the key players in the realm of Big Data ETL tools on AWS and uncover their unique capabilities tailored for seamless data integration and transformation.
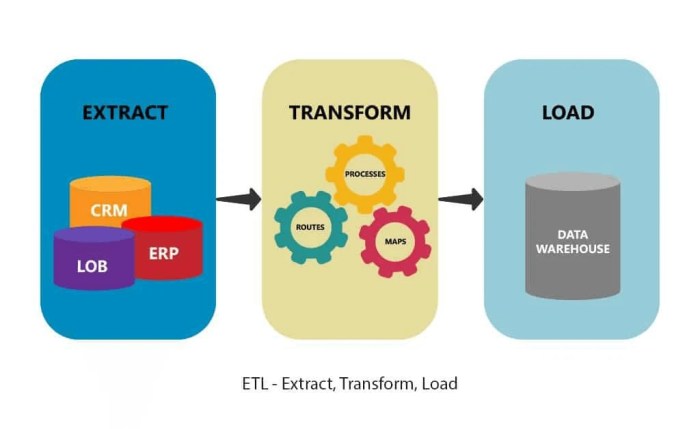
Overview of Big Data ETL Tools on AWS
Big Data ETL (Extract, Transform, Load) tools are essential components in the big data ecosystem that enable organizations to efficiently process large volumes of data from various sources, transform it into a usable format, and load it into a target data store for analysis. These tools play a crucial role in ensuring data quality, consistency, and reliability in a scalable and automated manner.
Popular ETL Tools on AWS
- AWS Glue: A fully managed ETL service that makes it easy to prepare and load data for analytics.
- Amazon EMR (Elastic MapReduce): An ETL tool that simplifies big data processing and analysis using Apache Spark and Hadoop.
- AWS Data Pipeline: A web service for orchestrating and automating the movement and transformation of data.
Importance of ETL Tools in the Big Data Ecosystem
ETL tools are crucial for organizations working with big data as they provide the following benefits:
- Efficient Data Processing: ETL tools streamline the process of extracting, transforming, and loading data, reducing the time and effort required for data preparation.
- Data Quality and Consistency: ETL tools help ensure data quality by cleansing, deduplicating, and standardizing data before loading it into the target system.
- Scalability and Automation: ETL tools enable organizations to scale their data processing capabilities as data volumes grow, while also automating repetitive tasks for increased efficiency.
AWS Data Pipeline

AWS Data Pipeline is a web service provided by Amazon Web Services that helps users automate the movement and transformation of data within the AWS ecosystem. It allows for the creation and scheduling of data-driven workflows, making it an essential tool for ETL processes in big data analytics.
Key Features of AWS Data Pipeline
- Ease of Use: AWS Data Pipeline offers a user-friendly interface for designing and managing complex data workflows without the need for extensive coding knowledge.
- Scalability: The service can handle large volumes of data and is designed to scale with the needs of the user, making it suitable for big data processing.
- Reliability: With built-in monitoring and error handling capabilities, AWS Data Pipeline ensures that data workflows run smoothly and efficiently.
- Integration: It seamlessly integrates with other AWS services such as Amazon S3, Amazon RDS, and Amazon EMR, enabling users to leverage the full power of the AWS ecosystem.
- Cost-Effective: Users only pay for the resources they use, making AWS Data Pipeline a cost-effective solution for ETL workflows.
Use Cases of AWS Data Pipeline
- Data Migration: AWS Data Pipeline can be used to migrate data between different storage systems or databases, ensuring a smooth and efficient transfer process.
- Data Processing: Organizations can utilize AWS Data Pipeline to process large volumes of data for analytics, reporting, or machine learning purposes.
- Real-Time Data Processing: The service can be employed to process streaming data in real-time, enabling timely insights and decision-making.
- Automated ETL: AWS Data Pipeline automates the ETL process, reducing manual intervention and improving overall efficiency in data processing tasks.
AWS Glue
AWS Glue is a fully managed ETL service provided by Amazon Web Services, designed to simplify the process of preparing and loading data for analytics. It allows users to create and manage ETL jobs, extract data from various sources, transform it, and load it into data warehouses for analysis.
Functionality of AWS Glue in ETL processes
AWS Glue offers a visual interface for creating ETL jobs, making it easy for users to define data sources, transformations, and targets. It automatically generates the code needed to execute these tasks, reducing the need for manual coding. AWS Glue also provides a flexible and scalable environment for running ETL jobs, ensuring efficient processing of large datasets.
Comparison of AWS Glue with other ETL tools on AWS
Compared to other ETL tools on AWS, such as AWS Data Pipeline, AWS Glue stands out for its serverless architecture and ease of use. It eliminates the need for provisioning and managing infrastructure, allowing users to focus on building ETL workflows rather than infrastructure maintenance. Additionally, AWS Glue offers built-in support for popular data sources and data formats, making it a versatile and efficient choice for ETL tasks.
How AWS Glue simplifies the ETL process for big data tasks, Big data ETL tools on AWS
AWS Glue simplifies the ETL process for big data tasks by providing a managed service that automates many aspects of ETL job creation and execution. Its visual interface and code generation capabilities reduce the time and effort required to set up and run ETL workflows. Additionally, AWS Glue’s scalability and integration with other AWS services make it well-suited for handling large volumes of data efficiently. Overall, AWS Glue streamlines the ETL process, enabling organizations to focus on deriving insights from their data rather than managing the intricacies of data preparation.
Amazon EMR

Amazon EMR (Elastic MapReduce) is a cloud-based big data platform provided by AWS, which allows users to process large amounts of data quickly and cost-effectively. It can be effectively utilized for ETL (Extract, Transform, Load) operations due to its scalability, flexibility, and performance capabilities.
Utilization of Amazon EMR for ETL operations
Amazon EMR can be used for ETL operations by running clusters of virtual servers to process and transform large datasets. Users can easily deploy Apache Hadoop, Apache Spark, or other frameworks on Amazon EMR to perform complex ETL tasks efficiently. Additionally, Amazon EMR integrates seamlessly with other AWS services, making it a powerful tool for data processing workflows.
Advantages of using Amazon EMR for processing big data
– Scalability: Amazon EMR allows users to scale clusters up or down based on the size of the data being processed, ensuring optimal performance.
– Cost-effectiveness: Users only pay for the resources they use, making Amazon EMR a cost-effective solution for processing big data.
– Flexibility: Amazon EMR supports a variety of big data processing frameworks, giving users the flexibility to choose the best tool for their specific ETL requirements.
– Performance: Amazon EMR is designed to handle large-scale data processing tasks efficiently, providing high performance and reliability.
Scenarios where Amazon EMR is preferred for ETL tasks on AWS
– Processing large volumes of data: Amazon EMR is ideal for handling ETL tasks that involve large datasets, as it can scale to accommodate the processing requirements.
– Complex ETL workflows: Amazon EMR is well-suited for scenarios where complex data transformation and processing are required, such as data cleansing, aggregation, and enrichment.
– Integration with other AWS services: Amazon EMR seamlessly integrates with services like S3, Redshift, and DynamoDB, making it a preferred choice for ETL tasks that involve multiple data sources and destinations.
AWS Glue vs. AWS Data Pipeline: Big Data ETL Tools On AWS

When comparing AWS Glue and AWS Data Pipeline, it’s essential to understand the differences in functionality and performance for ETL workflows. Both tools offer powerful capabilities for data processing on AWS, but they cater to different use cases and requirements.
Functionality
AWS Glue is a fully managed ETL service that makes it easy to prepare and load data for analytics. It provides a visual interface to create and run ETL jobs, along with built-in crawlers for discovering and cataloging metadata. On the other hand, AWS Data Pipeline is a web service for orchestrating data-driven workflows and automating ETL activities. It allows you to define data processing steps and dependencies using a simple drag-and-drop interface.
Performance Comparison
In terms of performance, AWS Glue is optimized for large-scale ETL workloads with built-in job monitoring, error handling, and automatic scaling based on demand. It leverages Apache Spark under the hood for fast and efficient data processing. On the other hand, AWS Data Pipeline is more suitable for simpler ETL tasks that require scheduling and resource management. It may not be as performant as AWS Glue for complex data transformations or processing.
Use Cases
AWS Glue is ideal for organizations that need a fully managed ETL service with advanced capabilities for data transformation and integration. It is well-suited for scenarios where you have large volumes of data that require complex processing logic. On the other hand, AWS Data Pipeline is a better choice for simple data movement and transformation tasks that can be automated through predefined templates and scheduling.
Overall, the choice between AWS Glue and AWS Data Pipeline depends on the specific requirements of your ETL workflows. If you need a robust and scalable ETL solution with advanced features, AWS Glue would be the preferred option. However, if you have simple data processing needs and require basic orchestration capabilities, AWS Data Pipeline could be more suitable for your use case.
In conclusion, Big data ETL tools on AWS play a pivotal role in optimizing data management processes, empowering businesses to harness the full potential of their data resources. With a diverse range of tools at their disposal, organizations can elevate their data processing capabilities to new heights.
When it comes to Amazon DynamoDB scalability , businesses need a database that can handle their growing data needs without compromising performance. With DynamoDB’s flexible scaling options, companies can easily adjust their capacity to accommodate fluctuating workloads, ensuring seamless operations at any scale.
Implementing data compression in Amazon S3 can significantly reduce storage costs and improve overall efficiency. By compressing files before storing them in S3, organizations can optimize their storage space and enhance data transfer speeds, leading to cost savings and faster access to critical information.
Real-time data processing in AWS empowers businesses to make informed decisions based on up-to-the-minute information. By leveraging AWS’s real-time data processing capabilities, companies can gain valuable insights in real-time, enabling them to respond swiftly to market trends and customer demands.




{kind=link}