Delving into Hadoop cluster setup on AWS EMR, this introduction immerses readers in a unique and compelling narrative, with a concise overview of the significance and benefits of setting up a Hadoop cluster on AWS EMR.
Exploring the key prerequisites, considerations, and permissions required for a successful setup, this guide will walk you through the step-by-step process of launching and configuring an EMR cluster on AWS. Dive into best practices for optimizing performance and cost efficiency, while also learning how to effectively manage, monitor, and troubleshoot common issues that may arise during operation.
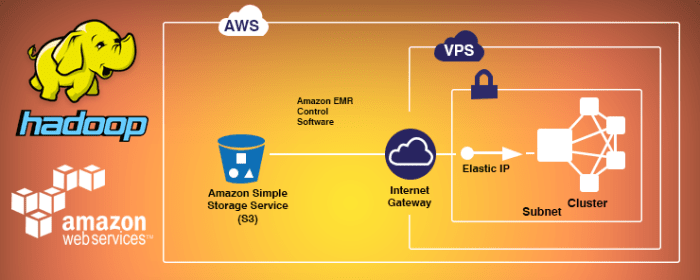
Overview of Hadoop Cluster Setup on AWS EMR

Hadoop is an open-source framework designed for distributed storage and processing of large data sets across clusters of computers. It is widely used in big data processing due to its scalability, fault tolerance, and cost-effectiveness.
Setting up a Hadoop cluster on AWS EMR (Elastic MapReduce) is crucial for organizations looking to leverage the power of Hadoop without the hassle of managing complex infrastructure. AWS EMR simplifies the process of deploying, managing, and scaling Hadoop clusters in the cloud, allowing users to focus on data analysis rather than infrastructure management.
Importance of Setting Up a Hadoop Cluster on AWS EMR
- Scalability: AWS EMR enables users to easily scale their Hadoop clusters up or down based on processing needs, ensuring optimal performance.
- Cost-Effectiveness: By using AWS EMR, organizations can avoid upfront infrastructure costs and only pay for the resources they use, making it a cost-effective solution for big data processing.
- Management Simplification: AWS EMR automates cluster provisioning, monitoring, and maintenance, reducing the operational overhead associated with managing Hadoop clusters.
Benefits of Using AWS EMR for Hadoop Cluster Setup
- Rapid Deployment: AWS EMR allows users to quickly launch Hadoop clusters with pre-configured templates, reducing setup time and enabling faster time-to-insights.
- Integration with AWS Services: AWS EMR seamlessly integrates with other AWS services like S3, DynamoDB, and Redshift, facilitating data ingestion, processing, and storage within the AWS ecosystem.
- Security and Compliance: AWS EMR provides built-in security features such as encryption, access control, and compliance certifications, ensuring data protection and regulatory compliance.
Preparing for Hadoop Cluster Setup: Hadoop Cluster Setup On AWS EMR

Before setting up a Hadoop cluster on AWS EMR, it is essential to ensure that all prerequisites are met and necessary considerations are taken into account.
When it comes to AWS analytics services, it’s essential to understand the differences between the various options available. You can check out this comprehensive AWS analytics services comparison to make an informed decision based on your specific needs and requirements.
Prerequisites for Setting Up a Hadoop Cluster on AWS EMR
- Amazon Web Services (AWS) account: To access AWS EMR services, you need to have an active AWS account.
- AWS Identity and Access Management (IAM) Role: Create an IAM role with the necessary permissions to access EMR services.
- Basic knowledge of Hadoop: Understanding the fundamentals of Hadoop and its ecosystem will be beneficial in setting up the cluster.
Key Considerations before Initiating the Setup Process
- Cluster configuration: Determine the size and type of instances required for your cluster based on workload and performance needs.
- Data storage options: Decide on the storage options such as Amazon S3 or HDFS based on your data requirements.
- Networking and security: Set up appropriate network configurations and security measures to protect your cluster and data.
Necessary Permissions and Access Requirements for AWS EMR
- EMR Full Access Policy: Assign the EMR_FullAccess policy to the IAM role to grant full access to EMR resources.
- EC2 Instance Profile: Create an EC2 instance profile with permissions to access necessary resources for the cluster.
- VPC and Subnet Configuration: Ensure proper VPC and subnet settings to allow communication within the cluster.
Setting up Hadoop Cluster on AWS EMR
Setting up a Hadoop cluster on AWS EMR involves several steps to ensure a smooth and efficient deployment. By following a structured approach, you can configure the cluster with Hadoop components and optimize performance while keeping costs in check.
Launching an EMR Cluster on AWS
Launching an EMR cluster on AWS involves the following step-by-step process:
- Create an AWS account if you do not already have one.
- Access the AWS Management Console and navigate to the Amazon EMR service.
- Click on “Create cluster” and select the appropriate cluster settings, including instance types, number of instances, and networking options.
- Choose the desired Hadoop distribution and version for your cluster.
- Configure additional software applications and tools that you want to include in the cluster, such as Apache Spark or Hive.
- Review and finalize the cluster configuration before launching it.
Configuring the Cluster with Hadoop Components
After launching the EMR cluster, you can configure it with Hadoop components to meet your specific requirements:
- Set up HDFS (Hadoop Distributed File System) for data storage and replication across nodes.
- Configure YARN (Yet Another Resource Negotiator) for resource management and job scheduling.
- Install and configure Hadoop ecosystem tools like Hive, Pig, and HBase for data processing and analytics.
- Tune the cluster settings for optimal performance based on workload characteristics and data processing requirements.
Best Practices for Optimization
Implementing best practices can help optimize performance and cost efficiency during the setup of your Hadoop cluster on AWS EMR:
- Right-size your cluster by choosing appropriate instance types and sizes based on workload demands.
- Use spot instances for non-critical workloads to save costs on EC2 instances.
- Enable auto-scaling to automatically adjust the cluster size based on workload requirements, ensuring efficient resource utilization.
- Leverage Amazon S3 for cost-effective data storage and seamless integration with EMR for data processing.
- Monitor cluster performance metrics and optimize configurations regularly to maintain efficiency over time.
Managing and Monitoring the Hadoop Cluster

Managing and Monitoring the Hadoop Cluster on AWS EMR is crucial to ensure optimal performance and reliability of your data processing tasks. This involves efficiently handling resources, scaling the cluster as needed, and closely monitoring its health to address any issues promptly.
Managing and Scaling the Hadoop Cluster
To manage and scale the Hadoop cluster on AWS EMR, you can utilize the following techniques:
- Utilize Auto Scaling: AWS EMR allows you to automatically add or remove instances based on the workload, ensuring optimal resource utilization.
- Adjust Instance Types: You can modify the instance types within the cluster to meet the specific requirements of your data processing tasks.
- Use Spot Instances: Take advantage of AWS Spot Instances to reduce costs for non-time-sensitive workloads.
- Leverage Reserved Instances: Utilize Reserved Instances to save costs for long-running workloads with predictable resource requirements.
By effectively managing and scaling your Hadoop cluster, you can optimize performance and cost-efficiency for your data processing tasks.
Monitoring Tools and Techniques, Hadoop cluster setup on AWS EMR
Monitoring the Hadoop cluster on AWS EMR is essential to ensure its health and performance. You can employ the following tools and techniques:
- AWS CloudWatch: Monitor key metrics such as CPU utilization, memory usage, and disk I/O to track the cluster’s performance.
- EMR Console: Utilize the EMR Console to view cluster metrics, logs, and configurations for real-time monitoring.
- Third-Party Monitoring Tools: Consider using third-party tools like Datadog or New Relic for advanced monitoring capabilities and alerts.
Regular monitoring of the Hadoop cluster helps in identifying and addressing any issues before they impact data processing tasks.
Troubleshooting Common Issues
During operation, you may encounter common issues with the Hadoop cluster on AWS EMR. Here are some insights on troubleshooting:
- Network Connectivity: Ensure proper network connectivity between nodes by checking security group settings and network configurations.
- Resource Allocation: Monitor resource usage and adjust configurations to prevent resource contention and bottlenecks.
- Data Node Failures: Address data node failures promptly by replacing failed instances and redistributing data across the cluster.
Proactive troubleshooting of common issues can help in maintaining the stability and reliability of your Hadoop cluster on AWS EMR.
In conclusion, setting up a Hadoop cluster on AWS EMR is a pivotal step in leveraging big data processing capabilities. By following this guide, you’ll be well-equipped to navigate the complexities of cluster management, monitoring, and troubleshooting, ensuring a seamless and efficient operation.
For efficient data archiving, Amazon S3 Glacier is a popular choice among businesses. Learn more about the benefits and features of Data archiving with Amazon S3 Glacier to see how it can streamline your data storage and retrieval processes.
When dealing with big data on AWS, choosing between AWS Glue and EMR can be a tough decision. This detailed comparison of AWS Glue vs EMR for big data will help you understand the strengths and weaknesses of each service to select the best fit for your project.




{kind=link}