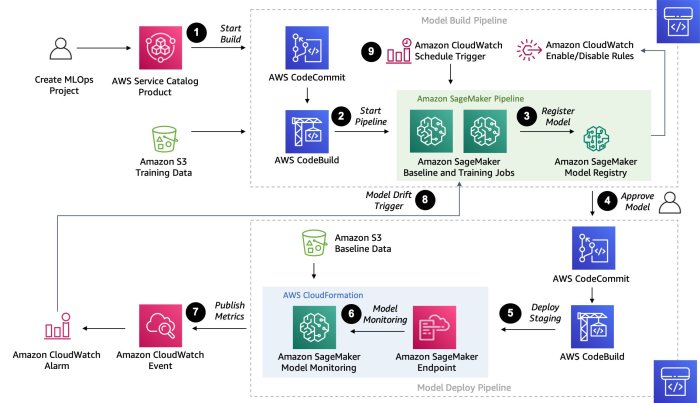
Machine learning with AWS SageMaker opens up a world of possibilities for optimizing your machine learning projects. Explore the key features, setup process, data preparation, model training, deployment, and monitoring in this detailed guide.
Overview of AWS SageMaker
AWS SageMaker is a fully managed service offered by Amazon Web Services that enables developers and data scientists to build, train, and deploy machine learning models quickly and easily. It provides a comprehensive set of tools and capabilities to streamline the machine learning workflow, from data preparation to model deployment.
Key Features of AWS SageMaker
- Integrated Jupyter Notebooks for data exploration and prototyping.
- Managed training environments with automatic model tuning.
- Pre-built algorithms for common machine learning tasks.
- Scalable model deployment with built-in monitoring and management.
Benefits of using AWS SageMaker
- Reduces the time and effort required to build and deploy machine learning models.
- Allows for seamless collaboration between data scientists and developers.
- Automates many aspects of the machine learning process, increasing efficiency.
- Provides cost-effective solutions for organizations looking to implement machine learning at scale.
Setting up AWS SageMaker

Setting up AWS SageMaker is a crucial step in leveraging its machine learning capabilities. Below are the steps to set up an AWS SageMaker environment and optimize it for your machine learning tasks.
Step-by-step Setup Guide
- Create an AWS account if you don’t have one already.
- Go to the AWS Management Console and navigate to Amazon SageMaker.
- Click on “Create notebook instance” to set up a new notebook instance.
- Choose an instance type based on your computational requirements.
- Configure the notebook instance settings such as instance name, IAM role, and network configuration.
- Review and create the notebook instance.
Configuration Options
Instance Type:
Select an instance type based on the computational power needed for your machine learning tasks.
Storage:
Configure the storage volume size and type for your notebook instance.
Networking:
Set up VPC, security groups, and other networking configurations for your instance.
Security:
Define IAM roles and policies to control access to your notebook instance.
Best Practices for Optimization
- Use spot instances for cost-effective training and inference.
- Monitor your notebook instance’s performance and adjust resources accordingly.
- Utilize SageMaker Studio for a comprehensive IDE for machine learning tasks.
- Regularly clean up unused resources to optimize costs.
Data Preparation in AWS SageMaker: Machine Learning With AWS SageMaker

When working with machine learning models in AWS SageMaker, data preparation is a crucial step to ensure the quality and accuracy of your models. In this platform, there are various tools and resources available to help you clean, transform, and normalize your data efficiently.
Data Cleaning
- Use SageMaker Processing Jobs to clean and preprocess your data before training your models.
- Utilize built-in algorithms and libraries for data cleansing tasks such as missing value imputation, outlier detection, and feature scaling.
- Take advantage of SageMaker Studio for interactive data exploration and visualization to identify and address data quality issues.
Data Transformation
- Apply feature engineering techniques to create new features from existing ones using SageMaker built-in capabilities.
- Leverage SageMaker Processing Jobs to perform data transformations at scale, especially when dealing with large datasets.
- Use SageMaker Data Wrangler for visual data preparation, transformation, and exploration tasks with a point-and-click interface.
Data Normalization
- Normalize your data using SageMaker Processing Jobs to bring all features to a similar scale and range, which can improve model performance.
- Explore SageMaker Autopilot for automated feature engineering and model selection, including normalization techniques tailored to your dataset.
- Consider using SageMaker Feature Store to store and share normalized features across different ML models for consistency.
Tips for Handling Large Datasets, Machine learning with AWS SageMaker
- Utilize SageMaker Ground Truth for data labeling workflows, especially when dealing with massive datasets that require manual annotation.
- Use SageMaker Data Wrangler to sample and pre-process large datasets efficiently, reducing computational costs and processing time.
- Consider distributed computing options like SageMaker Processing with Spark for parallel data processing to speed up data preparation tasks.
Model Training with AWS SageMaker
Training machine learning models using AWS SageMaker involves a streamlined process that leverages the power of cloud computing to accelerate model development and deployment. Let’s delve into the details of how this is achieved.
Algorithms and Frameworks Supported
AWS SageMaker offers a wide range of built-in algorithms and popular deep learning frameworks to support model training. These include but are not limited to:
- XGBoost
- Linear Learner
- Random Cut Forest
- TensorFlow
- PyTorch
Hyperparameter Tuning
Hyperparameter tuning is a crucial aspect of optimizing machine learning models for performance. AWS SageMaker simplifies this process by allowing users to define a hyperparameter tuning job and automatically search for the best set of hyperparameters. This helps in achieving higher model accuracy and efficiency.
Model Evaluation Techniques
Evaluating the performance of trained models is essential to ensure their effectiveness in real-world applications. AWS SageMaker provides various techniques for model evaluation, including:
- Metrics monitoring
- Model comparison
- A/B testing
By leveraging these evaluation techniques, users can make informed decisions regarding model deployment and further optimization.
Deployment and Monitoring in AWS SageMaker

When it comes to deploying and monitoring models trained with AWS SageMaker, there are several options and features that can help optimize performance and ensure reliability in production environments.
Deployment Options
- AWS SageMaker provides multiple deployment options, including real-time inference endpoints, batch transform jobs, and edge device deployment.
- Real-time inference endpoints allow you to deploy models for real-time predictions and integrate them into applications through APIs.
- Batch transform jobs enable you to process large volumes of data offline and generate predictions in bulk.
- Edge device deployment lets you deploy models directly to edge devices for local inference, reducing latency and enabling offline predictions.
Monitoring and Management
- Once a model is deployed, AWS SageMaker offers built-in monitoring capabilities to track model performance, detect drift, and ensure model accuracy over time.
- You can set up alerts based on predefined thresholds for monitoring key metrics such as prediction accuracy, latency, and data distribution.
- By continuously monitoring deployed models, you can identify issues early on, retrain models as needed, and maintain optimal performance in production.
Scalability and Reliability
- AWS SageMaker is designed for scalability and reliability in production environments, with features such as automatic model scaling based on demand and high availability for inference endpoints.
- Auto Scaling allows you to automatically adjust the number of instances serving predictions based on incoming traffic, ensuring cost efficiency and performance optimization.
- With built-in fault tolerance and redundancy, AWS SageMaker helps minimize downtime and ensures reliable model predictions even in high-traffic scenarios.
In conclusion, mastering AWS SageMaker can revolutionize the way you approach machine learning tasks, offering scalability, reliability, and efficiency. Dive into the realm of AWS SageMaker and elevate your projects to new heights.
When it comes to big data processing, AWS EMR is a top choice for many businesses. With its scalable infrastructure and efficient data processing capabilities, Big data processing with AWS EMR allows companies to analyze large datasets quickly and effectively.
Cost-efficient storage is essential for businesses managing large amounts of data. AWS offers a variety of storage services that are both reliable and cost-effective. By utilizing Cost-efficient AWS storage services , companies can save money while ensuring their data is secure and easily accessible.
Data compression plays a crucial role in optimizing storage space and reducing costs. Amazon S3 provides efficient data compression techniques that help businesses save on storage expenses. By implementing Data compression in Amazon S3 , companies can store more data while keeping costs down.




{kind=link}