SageMaker for machine learning workflows introduces a comprehensive platform that revolutionizes the building, training, and deployment of machine learning models. Dive into the realm of SageMaker and discover how it simplifies complex tasks with ease.
Overview of SageMaker for machine learning workflows
SageMaker is a comprehensive platform offered by AWS that simplifies the entire machine learning workflow, from data preprocessing to model deployment. It allows data scientists and developers to build, train, and deploy machine learning models at scale with ease.
Key Features of SageMaker
- Integrated Jupyter Notebooks: SageMaker provides built-in Jupyter notebooks for data exploration, visualization, and model building.
- Managed Training: Users can easily scale training jobs across multiple instances, optimizing resources and reducing training time.
- Pre-built Algorithms: SageMaker offers a library of pre-built algorithms for common machine learning tasks, saving time on model development.
- Automatic Model Tuning: The platform automates hyperparameter tuning to optimize model performance without manual intervention.
- Model Deployment: SageMaker streamlines the deployment process, allowing for easy deployment of models as RESTful APIs for real-time inference.
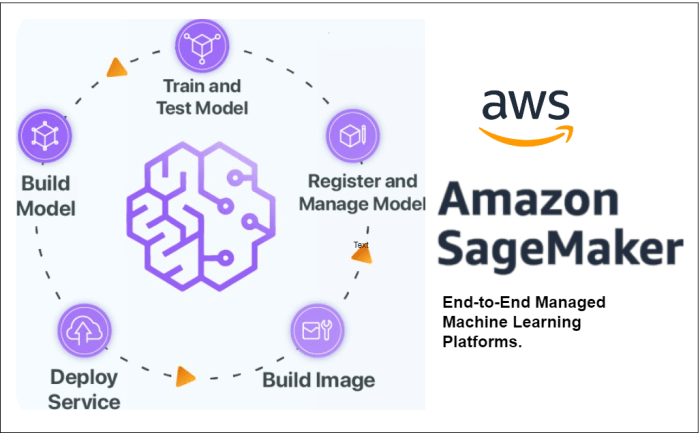
SageMaker components and architecture

SageMaker offers a variety of components that work together to streamline machine learning workflows and model development. Let’s delve into the different components and the overall architecture of SageMaker.
SageMaker Components
- Notebooks: SageMaker provides Jupyter notebooks for data exploration, model development, and experimentation.
- Data Processing: SageMaker offers data processing tools for data cleaning, pre-processing, and feature engineering.
- Training: SageMaker provides a managed training environment to train machine learning models at scale.
- Model Hosting: SageMaker enables deploying models for real-time or batch inference.
- Monitoring and Optimization: SageMaker allows monitoring model performance and optimizing model parameters.
Architecture of SageMaker
SageMaker’s architecture involves the seamless flow of data through different stages of model development. Data is typically stored in Amazon S3 and accessed by SageMaker components for processing, training, and deployment.
- Data Ingestion: Data is ingested from various sources and stored in Amazon S3 buckets.
- Data Preparation: Data is preprocessed, cleaned, and transformed using SageMaker data processing tools.
- Training: Models are trained on the preprocessed data using SageMaker’s training environment.
- Model Deployment: Trained models are deployed for inference, either in real-time or batch mode.
- Monitoring and Optimization: Model performance is monitored, and parameters are optimized for better results.
SageMaker’s architecture enables a smooth transition from data preparation to model deployment, facilitating efficient machine learning workflows.
Data Preparation and Preprocessing in SageMaker: SageMaker For Machine Learning Workflows
Data preparation and preprocessing are crucial steps in the machine learning workflow to ensure that the data is clean, formatted correctly, and ready for model training. In SageMaker, there are tools and capabilities that simplify these processes, making it easier for data scientists to work with their datasets efficiently.
Tools and Capabilities in SageMaker
When it comes to data preparation and preprocessing in SageMaker, there are several built-in features that help streamline the workflow. Some of the tools and capabilities include:
- Pre-built algorithms for common preprocessing tasks such as feature scaling, missing value imputation, and categorical encoding.
- Integration with popular data processing libraries like Pandas and NumPy for more customized data manipulation.
- Data transformation pipelines that allow for sequential execution of preprocessing steps.
Best Practices for Data Cleaning and Transformation
Before training a machine learning model in SageMaker, it is essential to follow best practices for data cleaning and transformation. Some of the key practices include:
- Removing outliers and irrelevant features that may negatively impact model performance.
- Handling missing values through imputation or deletion based on the nature of the data.
- Standardizing or normalizing numerical features to ensure consistency in scale.
Examples of Data Preprocessing in SageMaker
One of the ways SageMaker simplifies data preprocessing is through the use of built-in algorithms and pipelines. For example, data scientists can easily apply feature scaling and encoding transformations to their datasets with just a few lines of code. Additionally, SageMaker allows for the automation of preprocessing steps, saving time and effort in preparing data for machine learning models.
Training and tuning models using SageMaker

Training and tuning models using SageMaker involves leveraging its powerful capabilities to facilitate the process of model training and optimizing performance through hyperparameter tuning.
Model Training in SageMaker
SageMaker offers a wide range of algorithms and frameworks for training models, including popular options like XGBoost, TensorFlow, and Apache MXNet. Users can easily select the desired algorithm and framework based on the specific requirements of their machine learning task.
- SageMaker provides pre-built algorithms that are optimized for scalability and performance, allowing users to train models efficiently on large datasets.
- Users can also bring their custom algorithms and frameworks to SageMaker, giving them the flexibility to work with their preferred tools.
Hyperparameter Tuning in SageMaker
SageMaker automates the process of hyperparameter tuning, which involves optimizing the parameters that govern the learning process of a machine learning model. This automation helps users find the best set of hyperparameters to enhance model performance without the need for manual intervention.
- Through SageMaker’s hyperparameter tuning functionality, users can define the hyperparameters to be tuned, specify the range of values for each parameter, and set the objective metric to optimize.
- SageMaker then runs multiple training jobs with different hyperparameter configurations, evaluates the performance of each model based on the specified metric, and identifies the optimal set of hyperparameters that maximize model performance.
Deployment and monitoring of models in SageMaker

Deploying machine learning models into production is a crucial step in the workflow, and Amazon SageMaker provides various options for this process. Once deployed, monitoring and managing these models for performance tracking is essential to ensure optimal results.
Deployment Options in SageMaker, SageMaker for machine learning workflows
- SageMaker Endpoints: Allows you to create HTTPS endpoints to make real-time predictions using your trained model.
- SageMaker Batch Transform: Enables you to process large volumes of data offline and get predictions in batch mode.
- SageMaker Model Hosting: Hosts your trained model in a secure and scalable environment for easy access.
Monitoring and Management in SageMaker
- Amazon CloudWatch Integration: SageMaker integrates with CloudWatch for monitoring model performance metrics in real-time.
- Model Insights: Provides detailed insights into model performance, including accuracy, latency, and resource utilization.
- Automatic Scaling: Automatically scales resources based on demand to ensure optimal performance and cost efficiency.
Real-time and Batch Inference Capabilities
- Real-time Inference: SageMaker allows you to make real-time predictions using HTTP endpoints, suitable for applications requiring instant responses.
- Batch Inference: With Batch Transform, you can process large datasets and get predictions in bulk, ideal for scenarios where latency is not a concern.
- Model Monitoring: SageMaker provides built-in model monitoring capabilities to track model drift and performance degradation over time.
In conclusion, SageMaker for machine learning workflows emerges as a game-changer in the realm of machine learning, offering a seamless experience from start to finish. Embrace the power of SageMaker and elevate your ML endeavors to new heights.
When it comes to data processing, many organizations are turning to serverless computing solutions like AWS Lambda for data processing. This platform allows for seamless scalability and cost-effectiveness, making it a popular choice for handling large volumes of data efficiently.
For data archiving needs, Amazon S3 Glacier offers a reliable and secure solution. With its low-cost storage options and easy retrieval capabilities, it is ideal for businesses looking to store data for long-term archiving purposes.
When dealing with big data, the choice between AWS Glue vs EMR for big data can be a tough one. While AWS Glue is more suitable for data integration and transformation tasks, EMR excels in processing large datasets with its Hadoop-based framework. Choosing the right tool depends on the specific needs of your project.




{kind=link}