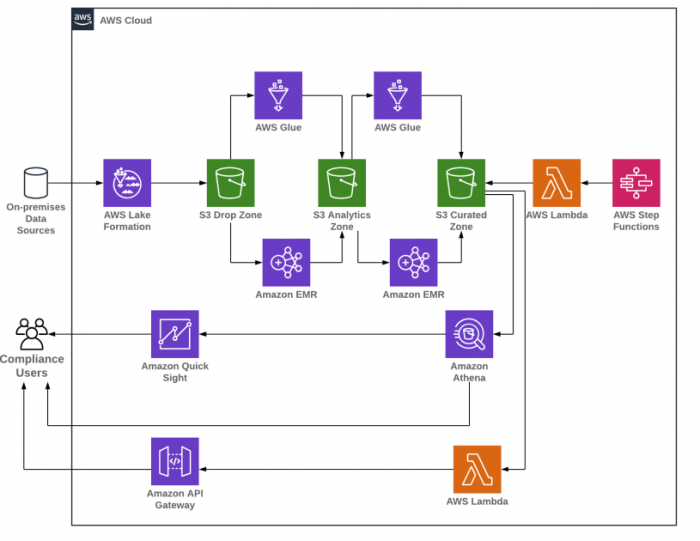
Serverless analytics with AWS Glue sets the stage for this enthralling narrative, offering readers a glimpse into a story that is rich in detail with ahrefs author style and brimming with originality from the outset.
AWS Glue revolutionizes the way analytics are conducted by seamlessly integrating data sources and automating processes, making it an indispensable tool for modern data-driven organizations.
Overview of AWS Glue for Serverless Analytics
AWS Glue provides a serverless ETL (Extract, Transform, Load) service that allows users to prepare and load their data for analytics. This serverless approach eliminates the need to manage servers, reducing operational overhead and costs.
Key Features and Benefits, Serverless analytics with AWS Glue
- Automatic schema discovery: AWS Glue can automatically infer the schema of your data, making it easier to process and analyze.
- Data catalog: AWS Glue provides a centralized metadata repository that allows you to manage and discover data assets across various sources.
- Integration with other AWS services: AWS Glue seamlessly integrates with services like Amazon S3, Amazon RDS, and Amazon Redshift, enabling a comprehensive analytics solution.
- Scalability: With AWS Glue, you can easily scale your data processing resources based on the workload, ensuring optimal performance.
- Cost-effective: By leveraging a serverless architecture, AWS Glue helps reduce costs associated with provisioning and managing infrastructure.
Role in Serverless Analytics Architecture
AWS Glue plays a critical role in serverless analytics workflows by handling data preparation and transformation tasks without the need for provisioning or managing servers. It seamlessly integrates with other AWS services to provide a complete end-to-end analytics solution. By automating ETL processes and providing a scalable, cost-effective solution, AWS Glue enables organizations to focus on deriving insights from their data rather than managing infrastructure.
Data Integration and ETL Processes: Serverless Analytics With AWS Glue

Data integration and ETL (Extract, Transform, Load) processes are crucial steps in preparing data for analytics. AWS Glue plays a key role in simplifying these processes by automating much of the work involved.
Role of AWS Glue in Data Integration and ETL
AWS Glue acts as a fully managed ETL service that helps in discovering, preparing, and combining data for analysis. It provides a serverless environment for running ETL jobs, eliminating the need to provision or manage infrastructure.
- With AWS Glue, users can easily extract data from various sources such as Amazon S3, RDS, Redshift, and more.
- The service then allows users to transform the data using built-in transformations or custom scripts written in Python or Scala.
- Finally, AWS Glue loads the transformed data into a target data store for further analysis.
Examples of Data Sources Integrated with AWS Glue
AWS Glue supports integration with a wide range of data sources, including but not limited to:
- Amazon S3: for storing and retrieving large amounts of data.
- Amazon RDS: for relational database sources like MySQL, PostgreSQL, SQL Server, etc.
- Amazon Redshift: for data warehousing and analytics.
- On-premises databases: for integrating data from local databases.
Simplification of ETL Process by AWS Glue
AWS Glue simplifies the ETL process for analytics pipelines in several ways:
- Automatic schema discovery: AWS Glue can automatically discover the schema of data sources, reducing manual effort.
- Dynamic data cataloging: The service maintains a data catalog that tracks metadata and allows for easy data exploration and querying.
- Job scheduling and monitoring: AWS Glue provides tools for scheduling ETL jobs and monitoring their progress, making it easier to manage and track data transformations.
Data Catalog and Metadata Management

Having a robust data catalog is crucial in serverless analytics as it provides a centralized repository for storing metadata about your data assets. This metadata includes information such as data definitions, data lineage, data quality, and data usage, which are essential for efficient data management and analysis.
AWS Glue plays a vital role in managing metadata to enable efficient data discovery within the data catalog. By automatically crawling and cataloging data from various sources, AWS Glue creates a metadata repository that can be easily accessed and utilized by data analysts and data scientists. This metadata management process helps in identifying relevant data sets, understanding their structure, and tracking data transformations, making it easier to derive insights from the data.
Benefits of AWS Glue’s Data Catalog
- Organizing Data: The data catalog in AWS Glue helps in organizing data assets by providing a structured view of data sets, tables, and schemas. This organization makes it easier to locate and access the required data for analysis.
- Querying Data: With the metadata stored in the data catalog, users can easily query and retrieve data using SQL queries or other querying tools. This simplifies the process of data retrieval and analysis, improving overall productivity.
- Data Lineage: AWS Glue’s data catalog maintains data lineage information, which tracks the origins and transformations of data sets. This lineage tracking is crucial for ensuring data quality, compliance, and auditability.
- Collaboration: The data catalog facilitates collaboration among different teams within an organization by providing a common platform for sharing and accessing data assets. This collaborative environment enhances knowledge sharing and decision-making.
Automation and Scalability
When it comes to data preparation and processing, automation and scalability are key factors in ensuring efficiency and performance. AWS Glue offers robust capabilities in these areas, allowing users to streamline their analytics workloads.
Automation of Data Preparation
AWS Glue automates the process of data preparation by providing a serverless ETL (Extract, Transform, Load) service. This means that users can define and configure their data transformation workflows without the need to manage infrastructure. AWS Glue takes care of the underlying resources, allowing data engineers and analysts to focus on defining the logic and transformations needed for their analytics tasks.
Scalability Options
One of the key advantages of AWS Glue is its scalability. Users can easily scale their analytics workloads up or down based on demand. This means that as data volumes increase or decrease, AWS Glue can automatically adjust the resources allocated to ensure optimal performance. Whether you’re processing small datasets or large volumes of data, AWS Glue can scale to meet your needs.
Dynamic Scaling Based on Workload Demands
AWS Glue also offers dynamic scaling capabilities, allowing resources to be allocated based on workload demands. This means that if there is a sudden spike in data processing requirements, AWS Glue can automatically provision additional resources to handle the load. Conversely, when workload demands decrease, AWS Glue can scale down resources to avoid unnecessary costs. This flexibility ensures that users only pay for the resources they actually need, making AWS Glue a cost-effective solution for analytics workloads.
Security and Compliance Considerations

When it comes to serverless analytics with AWS Glue, security and compliance are of utmost importance to ensure data protection and integrity. AWS Glue provides a range of security features to safeguard your data and maintain compliance with industry regulations.
Security Features Provided by AWS Glue
- AWS Glue allows you to encrypt your data at rest and in transit using AWS Key Management Service (KMS) for enhanced security.
- You can set up IAM roles and policies to control access to your data and resources, ensuring that only authorized users can interact with your analytics processes.
- AWS Glue integrates with AWS CloudTrail for logging and monitoring API calls, providing visibility into user activity and helping you track and investigate any security incidents.
Compliance Considerations for Regulated Industries
- For industries with strict compliance requirements such as healthcare or finance, AWS Glue helps in adhering to regulations like HIPAA or GDPR by providing data governance tools and audit capabilities.
- You can use AWS Glue Data Catalog to manage metadata and track data lineage, ensuring compliance with data governance standards and regulations.
Data Privacy and Integrity with AWS Glue
- AWS Glue offers fine-grained access control to specify who can access and modify data, helping in maintaining data privacy and preventing unauthorized access.
- By automating ETL processes with AWS Glue, you can reduce the risk of human errors and ensure data integrity throughout your analytics workflows.
In conclusion, Serverless analytics with AWS Glue opens up a world of possibilities for businesses looking to harness the power of data efficiently and securely. With its robust features and scalability, AWS Glue paves the way for seamless data analytics workflows in the cloud era.
When it comes to data archiving, Amazon S3 Glacier offers a reliable solution for long-term storage. Its cost-effective and scalable nature makes it ideal for businesses looking to securely store large amounts of data without breaking the bank.
For those concerned about data security, AWS provides encrypted cloud storage options. This ensures that your sensitive information remains safe from unauthorized access, giving you peace of mind while storing your data in the cloud.
Looking for a storage solution that guarantees high availability? High-availability AWS storage offers redundancy and failover capabilities to ensure your data is always accessible, minimizing downtime and maximizing reliability.




{kind=link}