Training ML models on AWS opens up a world of possibilities for data scientists and developers alike. From setting up your AWS account to optimizing your models, this comprehensive guide covers it all.
Learn about the benefits of using AWS, the steps to set up your account, best practices for data preparation, choosing the right ML framework, and techniques for training and optimizing ML models on AWS.
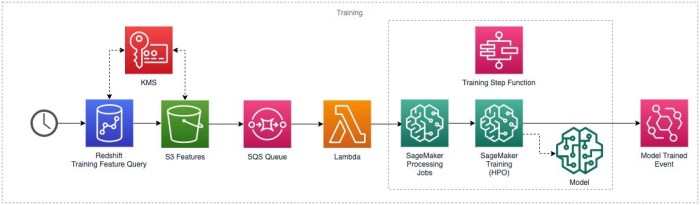
Overview of Training ML models on AWS

Training machine learning (ML) models on Amazon Web Services (AWS) offers numerous advantages due to the scalability, flexibility, and cost-effectiveness of the cloud computing platform. AWS provides a wide range of services and tools specifically designed for ML tasks, allowing data scientists and developers to efficiently build, train, and deploy ML models.
When it comes to AWS big data file storage, businesses need a reliable solution to handle large volumes of data. AWS offers a comprehensive service for storing and managing big data files efficiently. By utilizing AWS big data file storage , companies can ensure scalability and flexibility in handling their data storage needs.
Benefits of using AWS for training ML models
- Scalability: AWS allows users to easily scale computing resources up or down based on the requirements of the ML training process, enabling faster training times for complex models.
- Flexibility: With a variety of pre-built ML algorithms and frameworks available on AWS, developers can choose the best tools for their specific use case and quickly experiment with different models.
- Cost-effectiveness: AWS offers a pay-as-you-go pricing model, allowing users to only pay for the resources they use during the ML training process, reducing overall costs compared to on-premises solutions.
General process of training ML models on AWS
The process of training ML models on AWS typically involves the following steps:
- Data Preparation: Clean and preprocess data to ensure it is suitable for training the ML model.
- Model Training: Select an appropriate ML algorithm, configure training parameters, and start the training process using AWS services like Amazon SageMaker.
- Model Evaluation: Evaluate the performance of the trained model using metrics such as accuracy, precision, and recall to assess its effectiveness.
- Model Deployment: Once the model is trained and evaluated, deploy it to a production environment where it can make predictions on new data.
Examples of popular ML models trained on AWS
- Image Recognition: Convolutional Neural Networks (CNNs) trained on AWS using Amazon Rekognition for tasks like object detection and facial recognition.
- Natural Language Processing: Recurrent Neural Networks (RNNs) trained on AWS with Amazon Comprehend for sentiment analysis and text classification.
- Recommendation Systems: Matrix Factorization models trained on AWS using Amazon Personalize for personalized product recommendations.
Setting up AWS for ML model training

To begin training ML models on AWS, you first need to set up your AWS account, select the appropriate EC2 instance type, and configure security settings.
Setting up AWS Account
- Create an AWS account by visiting the AWS website and following the instructions to sign up.
- Provide payment information and set up billing preferences to ensure smooth usage of AWS services.
- Access the AWS Management Console to start setting up your resources for ML model training.
EC2 Instance Types for ML Model Training
- Choose EC2 instance types based on your ML model’s requirements, such as CPU or GPU optimized instances for faster processing.
- Popular EC2 instance types for ML training include p3, p2, g4, and c5 instances, each offering different levels of performance and cost.
- Consider the amount of memory, processing power, and storage needed for your specific ML tasks when selecting an instance type.
Configuring Security Settings on AWS
- Set up IAM (Identity and Access Management) roles to control access to AWS resources and services for different users.
- Utilize VPC (Virtual Private Cloud) to create a secure network environment for your EC2 instances and data during ML model training.
- Implement security groups to control inbound and outbound traffic to your EC2 instances, ensuring only authorized connections are allowed.
Data preparation for ML model training on AWS: Training ML Models On AWS

Preparing data before training ML models on AWS is crucial for achieving accurate and efficient results. It involves cleaning, transforming, and organizing data to ensure it is in the right format for training.
Best practices for data preparation
- Remove any irrelevant or redundant data to reduce noise and improve model performance.
- Normalize or scale numerical features to ensure all data points are on a similar scale.
- Handle missing values by imputing or removing them based on the context of the data.
- Encode categorical variables into numerical values using techniques like one-hot encoding.
- Split data into training and validation sets to evaluate model performance accurately.
Storing and accessing data efficiently on AWS
- Utilize AWS S3 (Simple Storage Service) to store large volumes of data securely and cost-effectively.
- Use AWS Glue for data cataloging and ETL (Extract, Transform, Load) processes to prepare data for training.
- Leverage AWS Data Pipeline for automating data workflows and managing dependencies between tasks.
Optimizing data pipelines for ML model training on AWS, Training ML models on AWS
- Monitor and optimize data processing workflows to identify and resolve bottlenecks for efficient training.
- Utilize AWS Lambda for serverless data processing to scale resources based on demand.
- Implement data versioning to track changes and ensure reproducibility in model training.
- Use AWS Step Functions to orchestrate complex workflows and manage state transitions in data pipelines.
Choosing the right ML framework on AWS
When it comes to training ML models on AWS, choosing the right ML framework is crucial for achieving optimal results. Popular ML frameworks available on AWS include TensorFlow, PyTorch, and MXNet. Each framework has its own advantages and disadvantages, so it’s important to consider several factors before making a decision.
Comparing and Contrasting TensorFlow, PyTorch, and MXNet
- TensorFlow:
- Advantages:
- Widely used and supported by a large community.
- Excellent for production-level deployment.
- Disadvantages:
- Steep learning curve for beginners.
- Less flexible compared to PyTorch.
- Advantages:
- PyTorch:
- Advantages:
- Dynamic computation graph allows for easy experimentation.
- Intuitive and beginner-friendly.
- Disadvantages:
- Less optimized for production deployment compared to TensorFlow.
- Smaller community support compared to TensorFlow.
- Advantages:
- MXNet:
- Advantages:
- Fast and scalable performance.
- Supports multiple programming languages.
- Disadvantages:
- Smaller user base compared to TensorFlow and PyTorch.
- Documentation can be lacking at times.
- Advantages:
Training and optimizing ML models on AWS
Training and optimizing machine learning (ML) models on AWS involves a series of steps to ensure the best performance and accuracy of the model. By utilizing the cloud-based resources and services provided by AWS, data scientists and developers can effectively train, optimize, monitor, and fine-tune their ML models for optimal results.
Training an ML model on AWS using a chosen framework
Training an ML model on AWS typically involves the following steps:
- Preparing the training data: Ensure that the data is properly formatted, cleaned, and ready for training.
- Choosing the right ML framework: Select a suitable framework such as TensorFlow, PyTorch, or Apache MXNet based on the requirements of the model.
- Setting up the training environment: Use AWS services like Amazon SageMaker to create a scalable and efficient training environment.
- Running the training job: Initiate the training process by specifying the model architecture, hyperparameters, and training data.
Optimizing ML models during the training process on AWS
To optimize ML models during the training process on AWS, consider the following techniques:
- Hyperparameter tuning: Use automated hyperparameter tuning services provided by AWS to find the best set of hyperparameters for your model.
- Distributed training: Utilize distributed training across multiple instances to speed up the training process and handle large datasets efficiently.
- Monitoring training metrics: Continuously monitor training metrics such as loss and accuracy to identify any issues and make adjustments as needed.
Monitoring and fine-tuning ML models on AWS for better performance
To monitor and fine-tune ML models on AWS for better performance, follow these strategies:
- Utilize Amazon CloudWatch: Use CloudWatch to monitor training jobs, set up alarms for specific metrics, and track the performance of your model in real-time.
- Implement model retraining: Periodically retrain your model with new data to ensure that it remains accurate and up-to-date.
- Perform A/B testing: Compare the performance of different versions of your model to identify the best-performing one and make informed decisions for optimization.
Mastering the art of training ML models on AWS can revolutionize your data projects. With the right tools and techniques, you can unlock the full potential of machine learning in the cloud. Dive in and start transforming your data into actionable insights today.
Automation is key in managing big data workflows effectively. AWS provides a powerful tool for automating workflows, streamlining processes, and improving productivity. With AWS big data workflow automation , organizations can simplify complex tasks and optimize their data processing operations.
Security is paramount when it comes to big data storage in AWS. Businesses must ensure that their data is protected from unauthorized access and cyber threats. With secure big data storage in AWS , companies can implement robust security measures to safeguard their valuable data assets.




{kind=link}